
What is Machine Learning: How I Explain the Concept to a Newcomer
What is machine learning, examples of its applications and what to do to work in the field


Explaining what machine learning is relatively simple, but the discussion must be calibrated according to the interlocutor. Some terms can be interpreted differently depending on the context, so it is right to look for a vocabulary that is as general as possible.
This article will target newcomers to the field: people who know little about quantitative analysis but who want to start approaching the subject for various reasons. In particular, I hope that this article can help young students to orient themselves in the university and workspace.
What is machine learning?
Machine learning is a branch of artificial intelligence, which in turn is a branch of computer science.
In machine learning, numerical data is used to train computers to complete specific tasks. The result is an algorithm that in turn uses a model of the phenomenon to find the solution to a problem. The term train is fundamental and it is the activity that most characterizes the field. Later we will see in detail what it means.
The difference between a piece of software that applies a specific rule to solve a task (for example, if a sentence contains the word “home”, create a “housing” category in an Excel spreadsheet) and a machine learning algorithm is that the latter does not have to be explicitly programmed to solve the problem.
A machine learning algorithm uses a model to mathematically infer rules in the data such that it can find a generic solution to the problem.
So let’s give a general definition of what machine learning is:
Machine learning is a branch of artificial intelligence that allows software to use numerical data to find solutions to specific tasks without being explicitly programmed to do so.
These solutions can be more or less accurate, and it is difficult to reach performances that are comparable to human ones.
However, this should not cause concern: most of the problems faced with machine learning offer performances that satisfy the general use case. Just think of product recommendations on Amazon or Gmail’s spam detection. We will see examples shortly.
What algorithm, model and performance are
Let’s clarify some concepts before going on.
An algorithm is nothing more than a series of instructions followed by a computer. It’s certainly a very overused word at the moment (Facebook algorithm, Twitter algorithm, and so on), but it’s actually a very simple concept.
A model is software that is inserted into the algorithm — we need it to find the solution to our problem. Since we often don’t know the real solution, these are called predictions.
Before being used to solve important problems, a model is subjected to a series of tests that evaluate its performance. This can only be calculated if we have a dataset that allows us to compare the real observation with the prediction of the model.
If the performance satisfies us then we will use the model in the so-called “production” environment (that is, in a real world application or alike), otherwise we can decide to train the model again or to discard it and go for another solution.

What does it mean to “train” a model?
As we have mentioned, numerical data is provided to a model to find generalizable solutions. The act of showing the data to the model and allowing it to learn from it is called training.
During training, the model tries to learn the patterns in data based on certain assumptions. For example, probabilistic algorithms base their operations on deducing the probabilities of an event occurring in the presence of certain data.
Training is controlled through hyperparameters, which allow us to adjust and calibrate how the model interprets the data and much more. Each model has its own hyperparameters.
One of the most important aspects of a data scientist’s job is to find the right set hyperparameters for a given model. It is often a very time-consuming task.
Once the model is tuned and trained, we can calculate its performance to assess whether its predictions differ substantially from the real, observed values. If we are satisfied with the results, the training phase is considered complete and we proceed with the following development phases.
A trained model behaves like any other software: it receives inputs and returns outputs. The inputs will be the data of the phenomenon, while the outputs will be the predictions.
Types of machine learning
Machine learning can be divided into three areas: supervised, unsupervised and reinforcement learning. Let’s see how the training of these algorithms differs according to the subcategory to which it belongs.
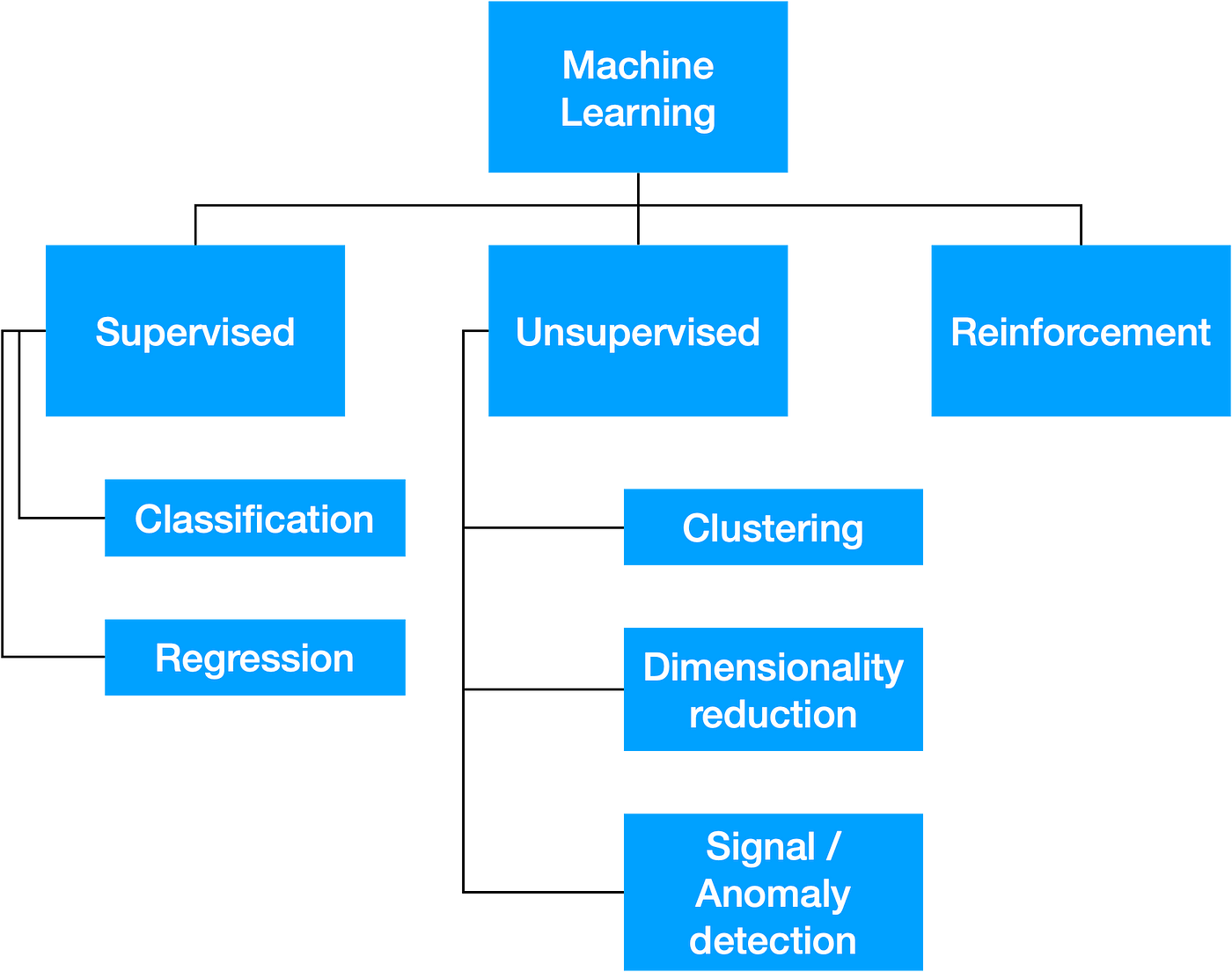
Supervised learning
Algorithms based on supervised learning need to be trained on data that contain the exact answer to the problem in order for them to understand the relationship between the latter and the phenomenon.
For example, a dataset for a supervised task might contain real estate data and price of each property. If we wanted to predict the price of a property, the algorithm would have to be trained to understand the association between features of the house, such as number of rooms, size and more, and the price.
In technical jargon, we say that the features of a phenomenon are part of the feature set (denoted by X, an independent random variable). The variable to be predicted is the dependent variable (because it depends on the characteristics), typically denoted by y.
Let’s sum up in one sentence what supervised learning is.
Supervised learning is a subcategory of machine learning that encompasses algorithms that require data in the form of X and y. X is the set of features of the phenomenon, y is the observation we want to predict.
A supervised algorithm learns the relationship between X and y and is able to predict a new y given an X not belonging to the training set.
The last part of the definition might be a bit tricky to understand, so I will try to explain better what X not belonging to the training set means.
The goal of a supervised machine learning algorithm is to predict something given a feature set of a phenomenon. During training, a predictive model learns the relationships between these data and its performance is assessed.
Metaphorically speaking,
a predictive model is like a child at school studying for his test. During the exercises (training), the child has access to the correct answers and is therefore able to refine his learning. At the final test, the child will be asked questions to which he won’t have access to the correct solutions.
X (final test questions) is not part of the training set (practice questions), and therefore the child (predictive model) will have to find the most precise solution (y) possible based on the learning he was subjected to previously.
Regression (prediction of a numerical value) and classification (prediction of a category) are examples of supervised learning.
Unsupervised learning
In this case our algorithms do not need to have access to the correct answer in our dataset, and therefore only need a feature set X.
How is it possible? Well because the logic of these algorithms is completely different compared to the supervised ones. Not all machine learning models have to behave like the child in the metaphor. In fact, unsupervised learning algorithms try to discover hidden patterns in the data to group, separate or manipulate the data in some way.
The beauty of these algorithms is that they don’t need human intervention to do their job. We just feed them our data in the correct format and we are done.
Unsupervised tasks are clustering, signal and anomaly detection and dimensionality reduction.
There are also algorithms that work partly in a supervised manner and partly in an unsupervised manner (they go by the name of semi-supervised algorithms), but these are typically ad-hoc algorithms created by large companies or very large teams.
Reinforcement learning
Reinforcement learning is often seen as a difficult area of machine learning and separate from the two mentioned approaches. The underlying concept actually is very simple: we program a software, called an agent, to learn how to complete a certain task in a specific environment and we offer rewards or punishments based on how it performs.
The idea is to reward the agent when it achieves a good result or punish it when it does something that hinders him from achieving it. In an iterative fashion, the model learns the rules for maximizing the fitness function, the mathematical function that defines the reward, and minimizes the error, that is the punishment. This allows for human-like learning: based on trial and error.
I highly recommend following his channel and watching this playlist where he programs an RF algorithm to play a game of Starcraft II.
Another video that is particularly effective at communicating the power of reinforcement learning is this one here, featuring cool robots :)
Machine learning application examples
To solidify our understanding of what machine learning is, let’s see some practical examples of how it is used in everyday life. Each of these use cases has implemented by a data science team, and if you choose to work in the field, you too could be working on such cool projects!
Anomaly detection
Are you familiar when your bank app notifies you of an abnormal transaction and asks your permission several times to be sure that you are actually authorizing it? I know you are.
Anomaly detection algorithms are programs that use data to capture behaviors that differ substantially from the usual ones. They are extremely useful for blocking an unauthorized transaction in the banking context, and equally useful when monitoring natural phenomena, such as with earthquakes and hurricanes.
Image and text classification
Have you ever wondered how the iPhone can use selfies for features like FaceID? While it’s not the only mechanism involved, Apple uses machine learning to classify the images that come from our camera. In this case, the classification is binary: presence or absence of a recognized face in the image.
Gmail has one of the most famous anti-spam algorithms. Just open your email account and check the spam inbox full of malicious emails. How does Google know that an email is potentially harmful and place it in the spam folder without our intervention?
It leverages machine learning algorithms trained and calibrated to classify the textual content of our emails. As mentioned above, model performance doesn’t have to be perfect to deliver real value to users. In fact, sometimes we may find ourselves having to manually place spam emails in the appropriate box.
Price prediction
Machine learning allows us to predict numerical values, such as the price of object.
It might seem like magic, but in the real estate industry, companies use machine learning algorithms to predict the price of houses and consequently refine their buying and selling strategies and gain a competitive advantage.
Custom content and UX
Websites such as Amazon track our buying and interaction behaviors. This allows them to train machine learning models that can understand what we like buying so that the system can recommend those possible choices, removing the need for search.
In fact, Amazon often proposes us products that “we might like” based on recommendation and clustering algorithms. Implementing such solutions is not easy but offering such an experience to our customers could really make a difference.
I’m sharing a video here that lists other machine learning applications if you are interested
How can you work in the field of machine learning?
To work in the field of machine learning you need to have knowledge in computer science, mathematics and statistics. The more specific this knowledge is, the better your chances of finding a well-paid and satisfying job will be. In fact, the data scientist, who is the main figure involved in this field, works precisely at the intersection of these three disciplines.
A data scientist carries out his job primarily by writing code, usually in Python or R. For this reason you must have good knowledge of software development logics, data structures and algorithms.
The most important areas of mathematics are certainly those of linear algebra, which allows the data scientist to exploit properties and operations on matrices, calculus, with the study of function and their optimization and probability.
It may seem very difficult to become a data scientist, but having specific knowledge of the industry of where you want to work is even more important.
In fact, it is not necessary to know all the notions of the aforementioned areas by heart, but it is enough to know the basics and help the company or the customer to seize the most profitable opportunities in the industry where it operates.
Today there are universities that prepare young students to work in the data science industry. Their curricula are varied, but all cover these mentioned disciplines.
For the self-taught, however, there are some very good online courses to start and consolidate the knowledge necessary to work in the sector. I can’t help but share Andrew Ng’s course on Introduction to Machine Learning Coursera. It is certainly one of the first steps to complete before embarking on the deep journey into the world of data.